
Introduction: Why AI integration in sharepoint is the need of the hour?
Sharepoint is one of the most widely used document library, knowledge management hub and project collaboration tool on intranet for any enterprise of SMBs all over the world. It’s the first choice of any company because of the extensive functionalities and support provided by Microsoft. However, over time organisations accumulate a massive amount of data and then it becomes very difficult for the administrator to organise it and also for the employees it becomes very difficult to find the right piece of information without going through multiple documents. The majority of the issue arises from the legacy keyword based search for documents and site pages which does not serve the purpose of giving the right information. For example if an employee wants to get information about vehicle lease policy and searches for vehicle lease policy, the current keyword based search will provide the documents and site pages where exact keywords are present, but if the search is done for car lease or bike lease or how can we lease a car from company, then the system will provide wrong documents of sometimes too many documents because of multiple keyword combinations results in poor user experience and wrong information.
Solution – LLM and vector based search (Semantic search)
Since we live in an exciting world now where LLMs are capable enough to understand the intent and type of query and provide the best possible results based on the query we can leverage this power to give our users a much better user experience, by providing them contextual answers based on semantic search. Here we explain how to integrate ChatGPT enterprise in sharepoint for natural language interactions with organisational data. Here ChatGPT enterprise is just taken as an example, however any LLM can be used which serves the purpose. Since we are focusing on microsoft stack, we will be using ChatGPT enterprise as an underlying LLM for the rest of the article to integrate with sharepoint and transform a static intranet sharepoint portal to an intelligent knowledge hub.
This Blog provides a technical developer – focused approach on how to integrate ChatGPT Enterprise into Sharepoint covering below points
- Architecture for integration of ChatGPT with sharepoint
- Multiple approaches which can be used along with pros and cons for each approach
- Implementation steps with code snippets
- Best practices and future trends and how we can further evolve it to make it much better.
- Detailed FAQs for developers and enterprise IT leaders who are looking for this digital transformation for their knowledge management hub.
Architectural Overview of AI + SharePoint Integration
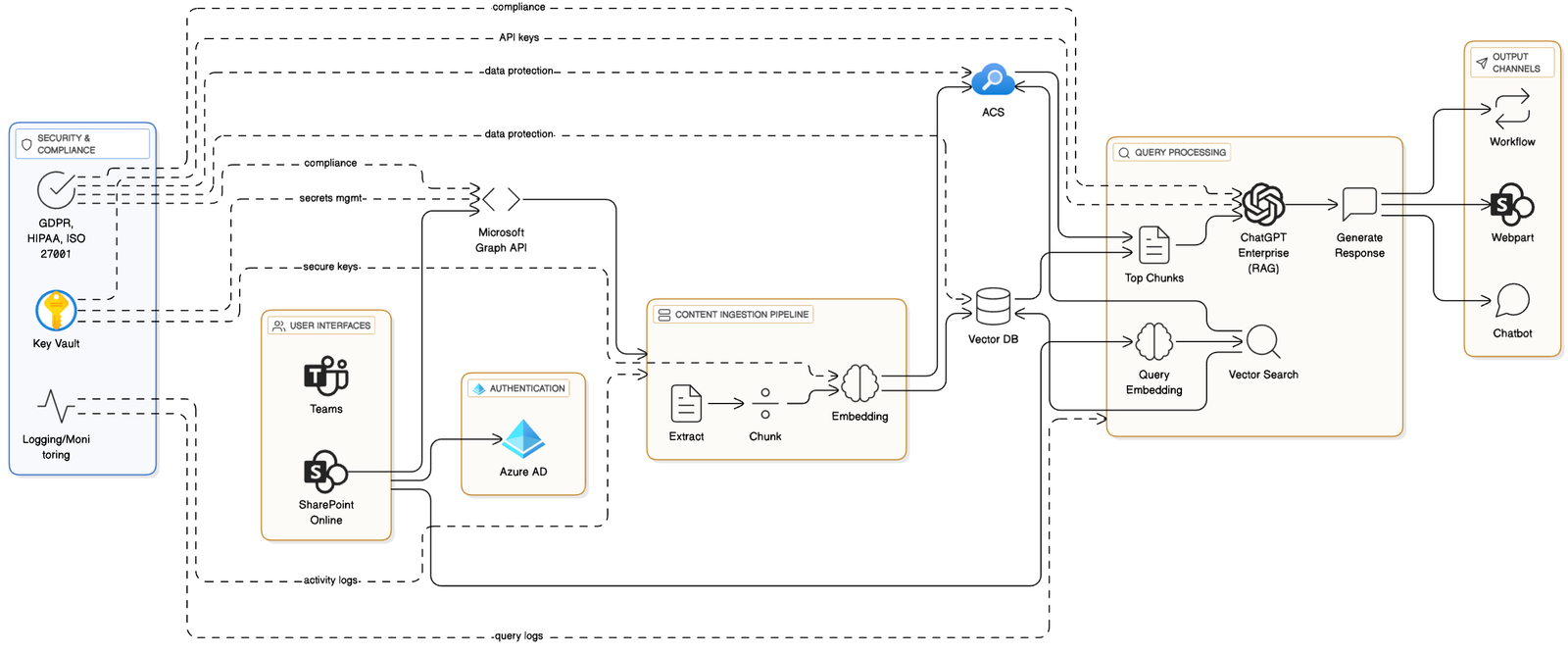
Core Components
There are five core layers for integration chatGPT enterprise with sharepoint architecture
ChatGPT Enterprise API
We need to get the API credentials for ChatGPT enterprise so that we can do two things, one more embedding and second is sending the prompt and getting natural language response from LLM.
Microsoft Graph API
Microsoft graph API is provided by microsoft which are used to generate access token, and using the access token it given programmatic access to sharepoint content such as documents, lists, sites etc from which we are read content. It also takes care of authentication and authorisation using azure Active directory which is essential for security.
Embeddings Generation
There are multiple embeddings models which are present in the market, but since we are focusing on chatGPT enterprise, so we will be using Azure OpenAI embeddings models (eg. text-embedding-ada-002), and once our data is converted to embeddings we can store it in Azure cognitive search or any other vector store.
Vector Store / Azure Cognitive Search (ACS)
Once our embeddings are ready we need to store it in a vector DB like Pinecone, Weaviate, FAISS, Milvus or in Azure cognitive search with vector fields. ACS has some advantages over other vector DBs for example it combines the legacy keyword search + semantic re-ranking + vector search in one query which increases the accuracy of outputs and enterprises using microsoft suite always prefers this to have their data always in microsoft services.
Integration Layer
Now that we have the embeddings stored in a Vector DB or Azure Cognitive Search (ACS), the next step is to integrate vector-based search and ChatGPT Enterprise into SharePoint.
Integration Apporaches
There are several approaches to achieve this, depending on the enterprise’s requirements for scalability, governance, and user experience.
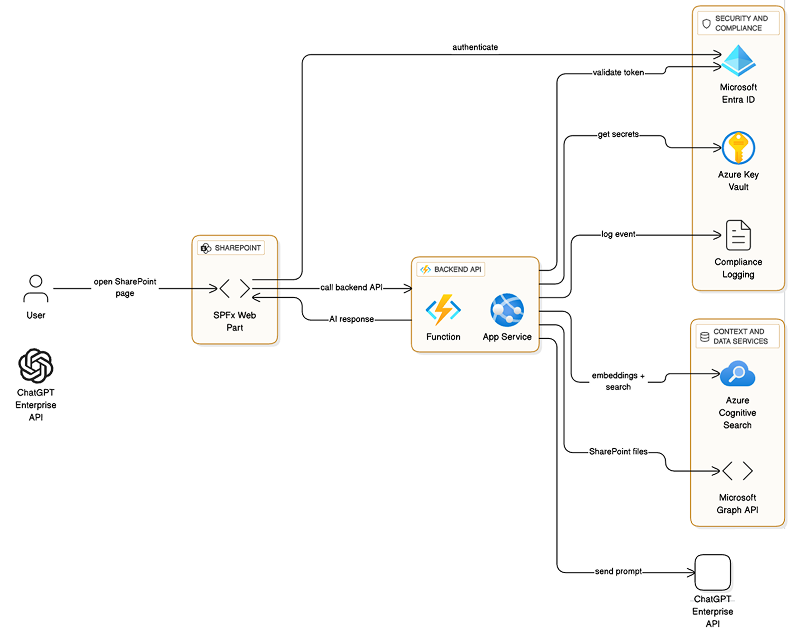
SPFx Web Parts / Extensions
Build custom SharePoint Framework (SPFx) web parts or extensions that integrate to your vector store/ACS and ChatGPT Enterprise API to get the results and show them to users.
Pros:
- Seamless native SharePoint experience.
- Respects SharePoint permissions & theming.
- Can be deployed tenant-wide for consistent adoption.
Cons:
- SPFx apps may struggle with scalability for heavy AI workloads.
- Requires experienced TypeScript + SPFx developers
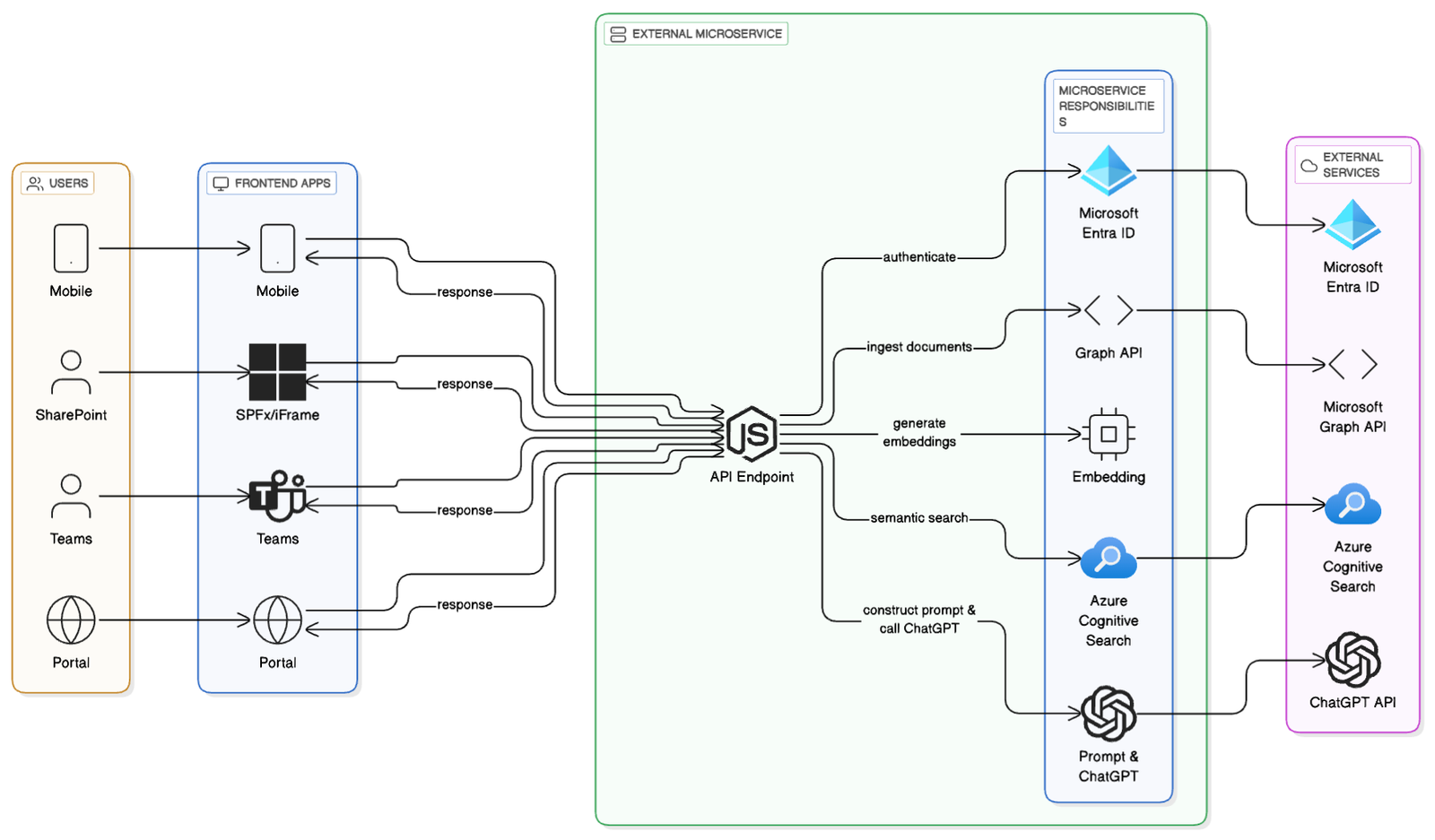
External Microservices (Node.js, .NET, Python)
Build a standalone API service (e.g., Node.js/Express, .NET Core, or Python FastAPI) that handles querying the embeddings from vector DB or ACS and sends the context with query to chatGPT and parse the response to show in sharepoint UI.
Pros:
- Highly scalable and reusable.
- Easier to implement complex logic (RAG, chunking, metadata filtering).
- Security best practices: API keys, logging, monitoring in one place.
- Supports multi-channel integration (SharePoint, Teams, mobile, external apps). One of the use case can be that these can be embedded in some other employee portal which is there not directly connected to sharepoint, even from there employees will be able to get the information without going to sharepoing site.
Cons:
- Requires separate DevOps / infrastructure (Azure Functions, Kubernetes, App Services).
- More complex lifecycle management (monitoring, patching, scaling).
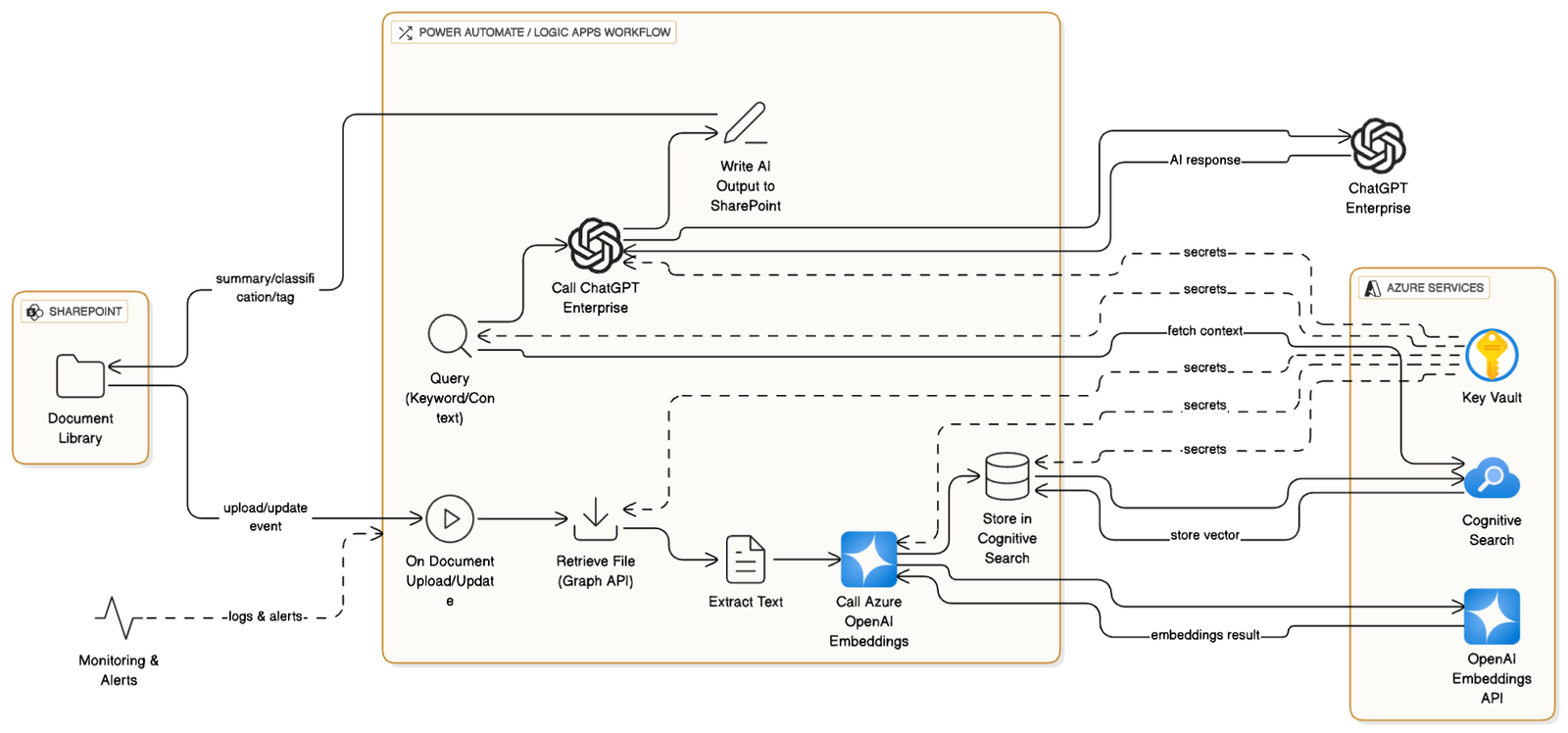
Power Automate / Logic Apps
Use low-code workflows to connect SharePoint events (upload, edit, approval) to Azure Cognitive Search + ChatGPT Enterprise.
Pros:
- Rapid prototyping wihout heavy coding.
- Great for document automation (summarization, classification, tagging).
- Easy for business users to build and maintain.
- Pre-built connectors for SharePoint and Graph API.
Cons:
- Limited flexibility for advanced AI use cases.
- Performance bottlenecks with large documents or high query volumes.
- More expensive for high-volume workloads due to per-run licensing.
- Harder to implement custom RAG logic (e.g., chunking + embeddings).
Teams + SharePoint Integration
Integrate ChatGPT as a Teams chatbot that can retrieve SharePoint content via Graph API + ACS.
Pros:
- Unified AI assistant across Microsoft 365 (not just SharePoint).
- Easy adoption since most enterprises already use Teams daily.
- Can leverage Team bots, adaptive cards, and notifications.
- Enables conversational search for SharePoint content.
Cons:
- Adds another interaction layer (not inside SharePoint UI).
- Requires Bot Framework / Azure Bot Service expertise.
Implementation for each integration approach
Since we have information about the pros and cons for each approach, once you have selected the best suitable approach for your organisation, please follow below steps to integrate ChatGPT in sharepoint using the correct approach.
SPFx Approach (SharePoint Native Web Part) — TypeScript + Secure Proxy
For SPFx, the front-end web part should not call OpenAI or ACS directly (avoid exposing keys). Instead, SPFx calls your microservice (Next.js/Node API or Azure Function). We’ll show:
- SPFx web part UI (React) calling backend /api/ask
- Backend handles the entire RAG flow (Graph token via Managed Identity/Client Credentials, embedding, ACS, ChatGPT)
- Authentication: Use Azure AD app or Managed Identity for microservice to call Graph and ACS
SPFx Web Part (React)
Filename – ChatAssistant.tsx
import * as React from "react";
import { PrimaryButton, TextField } from "@fluentui/react";
export default function ChatAssistant() {
const [q, setQ] = React.useState("");
const [a, setA] = React.useState("");
const [loading, setLoading] = React.useState(false);
async function ask() {
setLoading(true);
// Call tenant-hosted API (CORS must allow SharePoint domain)
const res = await fetch("/.auth/me"); // optional auth; or your custom endpoint
const token = null; // if using delegated auth, retrieve token; otherwise microservice uses its own creds
const r = await fetch("https://your-api.example.com/api/ask", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ question: q, siteId: "<siteId>", driveId: "<driveId>" })
});
const data = await r.json();
setA(data.answer);
setLoading(false);
}
return (
<div>
<TextField value={q} onChange={(_, v) => setQ(v)} placeholder="Ask about HR policies..." />
<PrimaryButton text="Ask" onClick={ask} disabled={loading}/>
<div>{a}</div>
</div>
);
}
Backend Proxy / Azure Function (recommended implementation)
Your backend should:
-
Own API keys and ACS admin key
-
Use either:
-
Client credential flow (app-only) to call Graph and access content, or
-
If you want to respect end-user permissions, implement delegated auth (more complex) where SPFx obtains user token (via MSAL) and forwards to backend
-
Example Azure Function (Node) endpoint POST /api/ask reuses the Next.js pipeline above.
Next.js / Node.js End-to-End Implementation (Microservice)
This is a standalone, reusable service that can be called from SharePoint (via an iframe or SPFx wrapper), Teams, or any front-end. We’ll show:
- Acquire Graph token (client credentials)
- List files & download content
- Extract text from Word/PDF
- Chunk text
- Generate embeddings (Azure OpenAI)
- Index into ACS
- Query ACS
- Build prompt + call ChatGPT (Azure OpenAI Chat Completions)
- Next.js API route + frontend
Dependencies & Setup
npm init -y
npm install node-fetch @azure/identity openai form-data mammoth pdf-parse dotenv
.env (Environment File)
AZURE_TENANT_ID=...
AZURE_CLIENT_ID=...
AZURE_CLIENT_SECRET=...
GRAPH_SCOPE=https://graph.microsoft.com/.default
AZURE_OPENAI_ENDPOINT=https://<your-resource>.openai.azure.com
AZURE_OPENAI_KEY=...
AZURE_OPENAI_EMBED_DEPLOYMENT=your-embedding-deployment
AZURE_OPENAI_CHAT_DEPLOYMENT=your-chat-deployment
AZURE_OPENAI_API_VERSION=2024-02-01
ACS_SERVICE=<your-acs-name>
ACS_ADMIN_KEY=<your-acs-admin-key>
ACS_INDEX_NAME=sharepointdocs
Get Microsoft Graph Access Token
// lib/graph.js
import fetch from "node-fetch";
import qs from "querystring";
export async function getGraphToken() {
const tokenUrl = `https://login.microsoftonline.com/${process.env.AZURE_TENANT_ID}/oauth2/v2.0/token`;
const body = qs.stringify({
client_id: process.env.AZURE_CLIENT_ID,
client_secret: process.env.AZURE_CLIENT_SECRET,
scope: process.env.GRAPH_SCOPE,
grant_type: "client_credentials"
});
const resp = await fetch(tokenUrl, {
method: "POST",
headers: { "Content-Type": "application/x-www-form-urlencoded" },
body
});
const data = await resp.json();
return data.access_token;
}
List Files in a Document Library
// lib/graph.js (continued)
export async function listDriveItems(siteId, driveId) {
const accessToken = await getGraphToken();
const res = await fetch(
`https://graph.microsoft.com/v1.0/sites/${siteId}/drives/${driveId}/root/children`,
{ headers: { Authorization: `Bearer ${accessToken}` } }
);
return res.json(); // value: [ { id, name, webUrl, size, ... } ]
}
Download File Content
export async function downloadFile(siteId, driveId, itemId) {
const accessToken = await getGraphToken();
const res = await fetch(
`https://graph.microsoft.com/v1.0/sites/${siteId}/drives/${driveId}/items/${itemId}/content`,
{ headers: { Authorization: `Bearer ${accessToken}` } }
);
const buffer = await res.arrayBuffer();
return Buffer.from(buffer);
}
Extract Text (DOCX/PDF)
// lib/extract.js
import mammoth from "mammoth";
import pdfParse from "pdf-parse";
export async function extractTextFromDocx(buffer) {
const result = await mammoth.extractRawText({ buffer });
return result.value;
}
export async function extractTextFromPdf(buffer) {
const data = await pdfParse(buffer);
return data.text;
}
// helper to choose based on file extension:
export async function extractText(buffer, filename) {
if (filename.endsWith(".docx")) return extractTextFromDocx(buffer);
if (filename.endsWith(".pdf")) return extractTextFromPdf(buffer);
// add support for .txt, .xlsx, etc.
return buffer.toString("utf8");
}
Chunking Functionality
// lib/chunk.js
export function chunkText(text, maxChars = 2000) {
const paragraphs = text.split(/n{2,}/).map(p => p.trim()).filter(Boolean);
const chunks = [];
let bucket = "";
for (const p of paragraphs) {
if ((bucket + "nn" + p).length > maxChars) {
if (bucket) chunks.push(bucket);
bucket = p;
} else {
bucket = bucket ? bucket + "nn" + p : p;
}
}
if (bucket) chunks.push(bucket);
return chunks;
}
Generate Embeddings
// lib/openai.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.AZURE_OPENAI_KEY,
baseURL: `${process.env.AZURE_OPENAI_ENDPOINT}`,
defaultHeaders: { "api-key": process.env.AZURE_OPENAI_KEY }
});
export async function createEmbedding(text) {
const resp = await client.embeddings.create({
model: process.env.AZURE_OPENAI_EMBED_DEPLOYMENT, // or name from Azure
input: text
});
return resp.data[0].embedding; // float32 array
}
Index Embeddings into Azure Cognitive Search
// lib/acs.js
import fetch from "node-fetch";
const ACS_BASE = `https://${process.env.ACS_SERVICE}.search.windows.net`;
const INDEX = process.env.ACS_INDEX_NAME;
export async function upsertChunk(docId, metadata, content, vector) {
const url = `${ACS_BASE}/indexes/${INDEX}/docs/index?api-version=2023-10-01-Preview`;
const body = {
value: [
{
"@search.action": "mergeOrUpload",
id: docId,
content,
metadata,
contentVector: vector
}
]
};
const res = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"api-key": process.env.ACS_ADMIN_KEY
},
body: JSON.stringify(body)
});
return res.json();
}
Query ACS with Question Embedding
export async function acsVectorSearch(queryVector, k = 3) {
const url = `${ACS_BASE}/indexes/${INDEX}/docs/search?api-version=2023-10-01-Preview`;
const body = {
vector: {
value: queryVector,
fields: "contentVector",
k
},
select: "id,content,metadata"
};
const res = await fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"api-key": process.env.ACS_ADMIN_KEY
},
body: JSON.stringify(body)
});
const json = await res.json();
return json.value; // array of documents
}
Compose Prompt + Call OpenAI completion API
export async function askChatGPT(question, chunks) {
const context = chunks.map((c, i) => `${i+1}. ${c.content}`).join("nn===nn");
const system = {
role: "system",
content: "You are an internal company assistant. Use only the provided context to answer. If context does not contain the answer, say you don't have enough information."
};
const user = {
role: "user",
content: `Context:n${context}nnQuestion: ${question}`
};
const resp = await client.chat.completions.create({
model: process.env.AZURE_OPENAI_CHAT_DEPLOYMENT,
messages: [system, user],
temperature: 0.0,
max_tokens: 800
});
// Azure SDK shape may vary; adjust accordingly
return resp.choices[0].message.content;
}
Next.js API Route
// pages/api/ask.js
import { createEmbedding, acsVectorSearch, askChatGPT } from "../../lib";
export default async function handler(req, res) {
try {
const { question } = req.body;
const qVec = await createEmbedding(question);
const hits = await acsVectorSearch(qVec, 4);
const answer = await askChatGPT(question, hits);
res.status(200).json({ answer, sources: hits.map(h => h.metadata) });
} catch (err) {
console.error(err);
res.status(500).json({ error: err.message });
}
}
Frontend Sample
// components/ChatBox.jsx
import { useState } from "react";
export default function ChatBox() {
const [question, setQuestion] = useState("");
const [answer, setAnswer] = useState("");
const [loading, setLoading] = useState(false);
async function ask() {
setLoading(true);
const res = await fetch("/api/ask", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ question })
});
const data = await res.json();
setAnswer(data.answer);
setLoading(false);
}
return (
<div>
<textarea value={question} onChange={(e) => setQuestion(e.target.value)} />
<button onClick={ask} disabled={loading}>Ask</button>
<pre>{answer}</pre>
</div>
);
}
Power Automate / Logic Apps Flow
Power Automate is useful for document ingestion and automated metadata enrichment rather than conversational chat (though you can still call an HTTP endpoint to return answers).
Typical Flow: Document Upload → RAG Summarize → Write back
- Trigger: When a file is created (SharePoint connector)
- Get file content: Get file content action (SharePoint)
- Extract text: Use Encodian connector (or Azure Function) to convert docx/pdf to text. (Power Automate doesn’t natively parse docx/pdf content into text reliably).
- Chunking & Embeddings:
- Action: Call an Azure Function or HTTP POST to your microservice that:
- Chunks the extracted text
- Calls Azure OpenAI embeddings endpoint for each chunk
- Uploads embeddings to ACS (or Pinecone)
- Write back: Update the file metadata (e.g., AI_Summary, Tags, Confidence) using Update file properties
HTTP Example Action to Create Embeddings (Power Automate)
- Action: HTTP (POST)
- URL:
https://your-api.example.com/api/ingest - Headers:
Content-Type: application/json
Body:
{
"siteId": "site-guid",
"driveId": "drive-guid",
"itemId": "item-guid"
}
Query Flow (Power Virtual Agents or HTTP Request)
If you want to offer a Q&A from Power Automate:
Use When an HTTP request is received trigger
Body example: { “question”: “What is our travel policy?” }
Within the flow: call your microservice /api/ask and return the answer in the HTTP response. This can power a Power Virtual Agents bot or an enterprise UI.
Pros of Power Automate: Business users can wire flows quickly; integrates easily with SharePoint connectors.
Cons: Harder for complex chunking/RAG logic; may incur costs at scale.
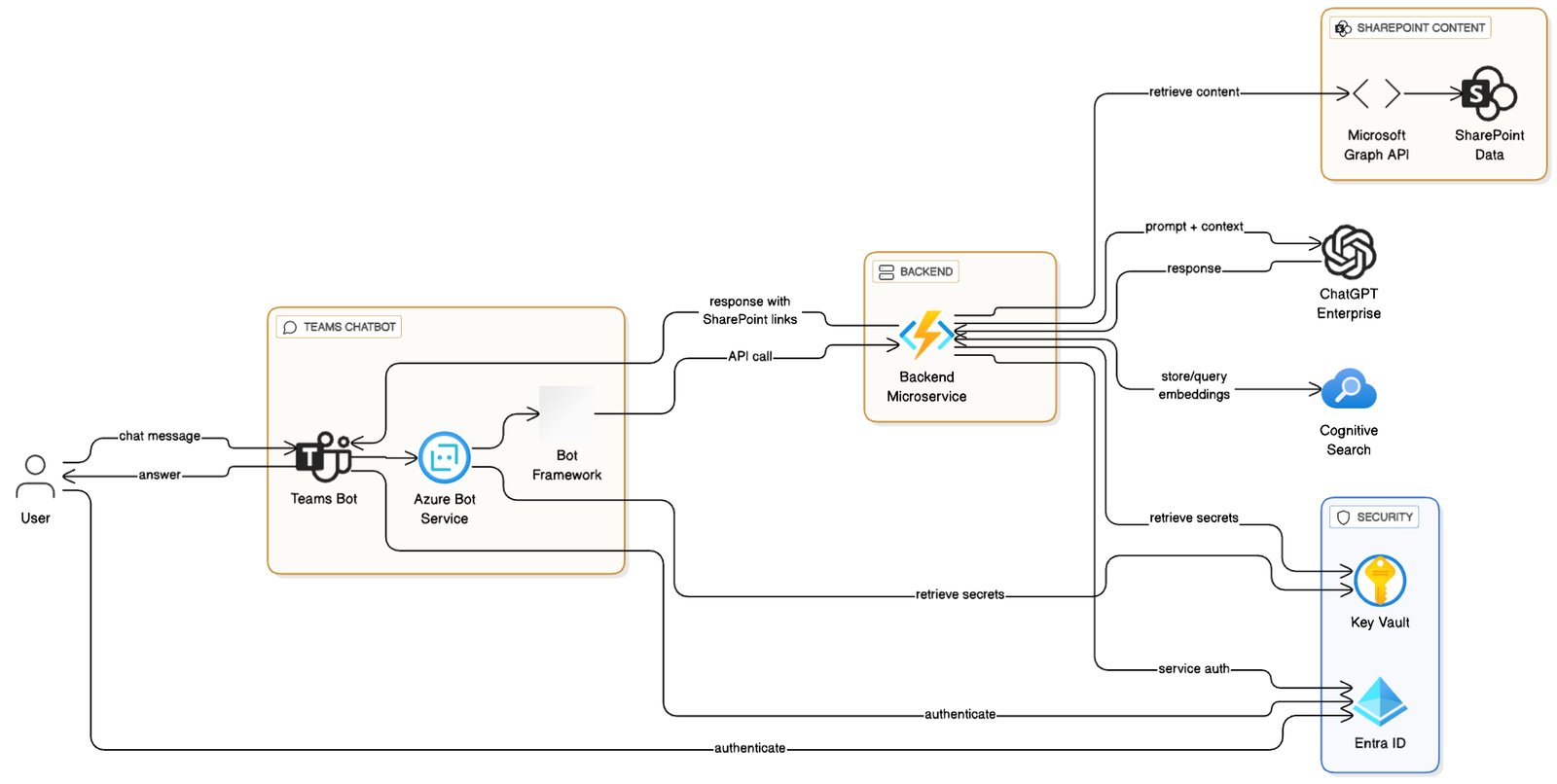
Teams Bot Integration (Bot Framework + RAG)
Create a Teams bot that answers questions by RAG-ing SharePoint content.
Architecture:
- Bot receives user message
- Bot (or backend) creates embedding for question
- Query ACS for top-K chunks
- Compose prompt and call ChatGPT
- Bot returns answer with source links (webUrl) or adaptive card with actionable items
Create Bot (Azure Bot Service) & Register in Azure AD
- Create Azure Bot resource (or Bot Channels Registration).
- Register messaging endpoint:
https://your-api.example.com/api/messages(Bot Framework adapter) - Configure Teams channel for the bot.
Bot Framework (Node.js)
// bot/index.js
import { BotFrameworkAdapter } from 'botbuilder';
import restify from 'restify';
import { handleUserMessage } from './handler';
const adapter = new BotFrameworkAdapter({
appId: process.env.MICROSOFT_APP_ID,
appPassword: process.env.MICROSOFT_APP_PASSWORD
});
const server = restify.createServer();
server.post('/api/messages', (req, res) => {
adapter.processActivity(req, res, async (context) => {
if (context.activity.type === 'message') {
const userText = context.activity.text;
const reply = await handleUserMessage(userText, context.activity.from);
await context.sendActivity(reply);
}
});
});
server.listen(process.env.port || 3978, () => {
console.log('Bot listening');
});
Sample handler
// bot/handler.js
import fetch from 'node-fetch';
export async function handleUserMessage(userText, user) {
const r = await fetch('https://your-api.example.com/api/ask', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ question: userText, userId: user.id })
});
const data = await r.json();
// Build an adaptive card or plain text
return data.answer + 'nnSources:n' + (data.sources || []).map(s => s.webUrl).join('n');
}
Use Cases for ChatGPT + SharePoint
Document Summarization
Document summarization use case is very relevant for any organisations employees, as a administrator you can give users to summarise a big document in 10 lines, or summarise a contract and fetch end dates, summary all files for example all invoices in a folder to get details of which vendor payment is not completed, or which vendors is paid most this year etc.
Metadata Tagging
Metadata is important for documents uploaded to sharepoint since it gives like an overview to our system about what the document is about. When an organisation reaches a scale where there are multiple thousands of documents being added to the knowledge management, it becomes very difficult to manually add meta data, so AI assigns categories, sensitivity labels, or keywords automatically.
Knowledge Retrieval
Employees ask: “What’s our travel reimbursement policy?” → AI retrieves answer from HR SharePoint library. This is the most useful and most user centric use cases which will affect most number of users of sharepoint. Instead of keyword based search this implements a semantic search and not just search and give documents, it also can extract and give a short answer to user, so that user does not have to go through entire documents which in turn increases productivity of employees.
Compliance & Risk Management
This use case is mostly focused towards compliance teams which can save time and reduce errors by just asking the AI highlights potential non-compliant clauses in documents.
Onboarding & Training
New hires often struggle to find answers in large HR portals. An AI chatbot integrated into SharePoint can simplify onboarding by providing instant, conversational responses based on company HR documents. Using Microsoft Graph, the chatbot retrieves policies and handbooks stored in SharePoint, indexes them with Azure Cognitive Search, and leverages ChatGPT Enterprise to deliver clear, grounded answers. Instead of emailing HR with questions like “How many leave days do I get?”, employees get quick, accurate replies directly inside SharePoint or Teams—reducing HR workload, speeding up onboarding, and ensuring consistent communication across the organization.
Future of AI in Sharepoint
Organizations will adopt private or fine-tuned models for sensitive domains (legal, pharma, defense). These can run in-cloud or on-prem (with significant infra). The hybrid approach—keeping retrieval private (vectors & metadata in-house) and calling a hosted LLM—is common. Along with this we expect that AI will handle multimodal content (documents, images, audio, video) and perform multi-step agentic tasks: “Read the contract, extract obligations, generate a review checklist, and open a ticket.” Agents orchestrating APIs, approval flows, and human-in-the-loop steps will become common.
FAQs — Short, Practical Answers
Question 1 – Can ChatGPT Enterprise integrate directly into SharePoint?
Answer – Yes. You can integrate ChatGPT Enterprise into SharePoint using SPFx web parts (native UX), embedded web apps (iframes or custom web parts), or low-code connectors that call your backend. For production-grade, use a backend proxy (Azure Function / microservice) to handle embeddings, vector search (ACS or vector DB), and ChatGPT API calls so secrets aren’t exposed client-side.
Question 2 – What’s the difference between SPFx and embedding an external app?
Answer – SPFx = native SharePoint web part/extension: seamless UI, easier tenant deployment, respects SharePoint context. External app (Next.js/React) = runs outside SharePoint (App Service, Vercel), embedded via iframe or SPFx wrapper: more architectural flexibility, easier multi-channel reuse, simpler to scale and manage heavy compute. Best practice: use external microservice for heavy RAG/AI logic and call it from SPFx for native experience.
Question 3 – How do I secure API keys in SharePoint?
Answer – Never store keys in client-side code. Use server-side services (Azure Functions, App Service) with secrets in Azure Key Vault or platform-managed environment variables. Prefer Managed Identity for Azure resources to call Microsoft Graph or ACS. Enforce network controls (private endpoints), role-based access, and minimal permission scopes.
Question 4 – Can ChatGPT read SharePoint libraries?
Answer – Yes—indirectly. Your backend uses Microsoft Graph (app-only or delegated tokens) to fetch file content, then extracts text and uses embeddings to index/search. ChatGPT itself doesn’t “read” SharePoint unless you supply the retrieved context in the prompt (RAG).
Question 5 – Is Microsoft Copilot the same as ChatGPT?
Answer – No. Copilot is Microsoft’s integrated assistant across M365 built on Microsoft’s LLM stack and product integrations; it’s OOTB for M365 tasks. ChatGPT Enterprise (OpenAI) is a flexible LLM you can call via APIs and customize with RAG, prompt engineering, and private knowledge. Copilot is great for built-in scenarios; ChatGPT Enterprise gives more control for custom/differentiated workflows.
Question 6 – How do I authenticate with Graph API?
Answer – Two common patterns:
1. App-only (client credentials): Good for background ingestion and indexing tasks (service principal). Requires admin consent for scopes like Sites.Read.All.
2. Delegated / On-behalf-of: Use when you must enforce user-level security trimming in realtime. SPFx can obtain user tokens (MSAL) which you can forward via on-behalf-of flow to backend services. Choose based on whether you need per-user permission enforcement.
Question 7 – Can Power Automate trigger ChatGPT workflows?
Answer – Yes. Power Automate can call HTTP endpoints (your microservice) or Logic Apps can orchestrate Azure Functions to generate embeddings, call ACS, then call ChatGPT. Power Automate is ideal for document-event-driven automation (on upload → summarize/tag), but complex RAG logic is easier to encapsulate in a backend service.
Question 8 – How do I chunk large documents for AI processing?
Answer – Split by semantic boundaries (paragraphs/sections) and by token-size targets (use tokenizer like tiktoken). Typical approach: chunks of ~500–1,000 tokens with small overlap (50–100 tokens) to preserve context. Store chunk metadata (doc ID, offsets) so you can trace answers back to source fragments.
Question 9 – What’s the latency for AI responses?
Answer – Latency components: embed generation (~100–300ms per chunk), vector search (~10–100ms), and chat completion (hundreds ms to several seconds depending on model & context size). Expect 500ms–3s for typical RAG Q&A in production; plan UX (loading states) and caching to improve perceived performance.
Question 10 – How do I ensure compliance with GDPR?
Answer – Minimize personal data in prompts, keep data residency considerations (use Azure regions that meet requirements), log access with audit trails, use Data Processing Agreements (DPA) with provider, and implement retention/erasure policies. If using ChatGPT Enterprise, verify contractual data handling guarantees (no training on your data) and prefer Azure OpenAI if you need Azure’s compliance posture.
Question 11 – Can ChatGPT Enterprise work offline with SharePoint Server (on-prem)?
Answer – Not typically—ChatGPT Enterprise is a hosted API. For fully on-prem environments, options are: deploy a private LLM that you host on-prem (requires heavy infra), or set up a secure hybrid architecture where on-prem SharePoint content is sync’d (via secure gateway) to an Azure-hosted ingestion pipeline (respecting compliance).
Question 12 – What’s the cost of integrating ChatGPT with SharePoint?
Answer – Costs include: LLM usage (tokens for embeddings + chat), Azure Cognitive Search or vector DB costs, compute/hosting (Azure Functions, AKS), storage, and engineering/maintenance. RAG strategies (chunk size, top-k) and caching reduce per-query token usage. Estimate with pilot data and monitor consumption carefully.
Question 13 – How do I handle sensitive data?
Answer – Filter/redact PII before sending data to LLMs when possible. Use classification to mark sensitive documents and exclude them from indexing or route them through stricter review. Enforce role-based access and encrypt data in transit and at rest. Consider policy-based prompt redaction and human-in-the-loop review for high-risk responses.
Question 14 – Can ChatGPT generate SharePoint pages automatically?
Answer – Yes—programmatically. You can use Graph API to create pages, lists, and content; ChatGPT can draft content or templates which your backend can persist into SharePoint via Graph. Ensure content validation and approvals are in place to avoid publishing inaccurate or non-compliant content.
Question 15 – Can I integrate ChatGPT with Teams + SharePoint simultaneously?
Answer – Yes. Build a single backend RAG service and expose it to multiple front-ends: SPFx webparts in SharePoint, Teams bots/adaptive cards, or external portals. Reuse indexing assets (ACS/vector DB) so all channels share the same knowledge base and metadata.
Question 16 – Do I need developers, or can IT admins do it with Power Automate?
Answer – Both. Power Automate is enough for simple document automation (summaries, tags). For conversational RAG, large-scale ingestion, security-trimmed search, or custom UX, developers are required. Most real-world, secure deployments are hybrid: Power Automate for simple flows + developer-built microservices for core RAG/LLM logic.
Question 17 – What’s the role of RAG in SharePoint AI?
Answer – RAG (Retrieval-Augmented Generation) is the architectural pattern that grounds LLM responses in your company content. In SharePoint scenarios, RAG retrieves relevant document chunks (via embeddings + vector search) and provides them as context to ChatGPT so answers are factual and traceable to source docs.
Question 18 – How do I fine-tune ChatGPT for company-specific knowledge?
Answer – Yes you have multiple option to do it Options:
- Fine-tuning (if provider supports) on internal corpora.
- Better: use RAG + system prompts and a private knowledge base to avoid retraining while still achieving grounded answers.
- Some platforms support private fine-tuned models or instruction-tuning; evaluate privacy, cost, and maintenance trade-offs.
Question 19 – Can I use Azure OpenAI instead of ChatGPT Enterprise?
Answer – Yes. Azure OpenAI exposes similar models via Azure subscriptions and integrates well with Azure services (Key Vault, Managed Identity). Choice depends on contract, compliance, region support, and platform features. Many enterprises prefer Azure-hosted models for tighter Azure ecosystem alignment.
Question 20 – What’s the best architecture for large enterprises?
Answer – A common enterprise-grade pattern:
- Ingestion pipeline (Graph → extract → chunk → embeddings) as batch/stream, storing vectors in ACS (or vector DB).
- Microservice RAG API that handles query embedding, vector search, prompt composition, LLM call, security trimming, and auditing.
- Multi-channel front-ends: SPFx for native UX, Teams bot for conversational access, and external apps.
- Use Key Vault, Managed Identities, private endpoints, logging, and monitoring. Scale with AKS or serverless functions and use caching & rate-limiting.
Conclusion
Integrating ChatGPT Enterprise into SharePoint transforms how employees access, manage, and use knowledge. Depending on which approach you choose there are some pros and cons which you can check and take a informed decision before implementing the approach in your organisation.
As a development and integration services provider, we help enterprises build custom AI solutions that unlock the full potential of SharePoint. From architecture design to SPFx development, API integration, and enterprise rollouts, our team ensures your AI projects are secure, scalable, and impactful. We have an extensive experience in integration of chatGPT and other LLMs in sharepoint.
Ready to explore ChatGPT + SharePoint for your organization? Contact us today to discuss your integration journey.

Co-Founder Simplileap
Passionate Full Stack Developer with an unwavering enthusiasm for technology and a relentless drive for continuous learning with more than 10 years of experience in Web Development, SEO and Software Development. Committed to pushing boundaries, I thrive in dynamic environments where I can leverage my expertise in front-end and back-end development to create innovative solutions. With a strong foundation in various programming languages and frameworks, I am dedicated to staying updated with the latest industry trends and incorporating them into my work.


